





Machine learning is powered by data. Given appropriate data, a machine learning algorithm can accurately process huge quantities of information. However, a task like false alarm filtering requires two things for it to work: first, we need raw data - in our case, the images from a security camera alarm. Second, we need labels for the data, like the coordinate locations of different objects in the alarm images. These data labels are known as ‘supervision’, and in turn, the process of teaching an algorithm to accurately recognise objects is known as ‘supervised learning’.
These labels often require human input since, unlike an untrained algorithm, we humans already have the knowledge required to recognise objects in an image and draw boxes around them. We call this process of gathering human labels 'data annotation' or ‘data labelling’. Let's dive into what goes on in this process.
If you want to learn even more about machine learning, check out our free ebook, Machine Learning Explained:

How data labelling works
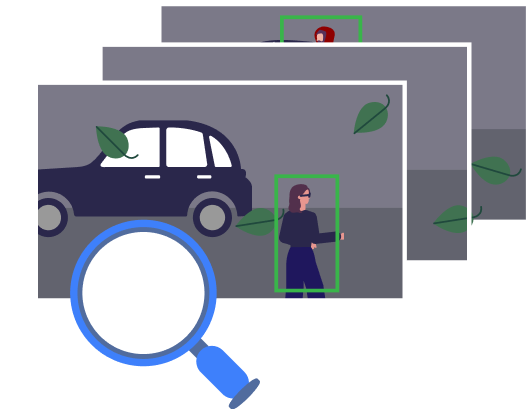
We start off with an alarm comprised of a set of images. For privacy purposes, we first pass these images through an algorithm that blurs peoples' faces if they're clearly visible. After that, these images are shown to our labelling team. They are required to draw boxes (called bounding boxes) around people and vehicles in the image and mark each box according to the appropriate class (we have one class for people and a few classes for different types of vehicles). We call these labels the localisation and classification labels respectively: i.e. where something is and what it is.
On top of this, our labellers also provide something called a 'track id'. What is this? Well when you're looking at just a single image, we can safely assume that each box belongs to a unique object. But when you're looking at a series of images from an alarm, it's useful to link boxes between the different frames so that the algorithm we're training later on can understand that two boxes in two different images are actually highlighting the same person/vehicle. We call the series of boxes associated with a unique object across a set of frames a 'track' and hence a 'track id' is a unique identification number that allows us to associate boxes with a track.
 Above: two objects have been localised in bounding boxes, classified as people and tracked over two images.
Above: two objects have been localised in bounding boxes, classified as people and tracked over two images.
Making data annotation faster
So our labellers have to provide the localisation, classification, and track id labels for a lot of objects. They're very good at this and very fast, but we're constantly trying to improve our data annotation application to make it easier for them to provide these labels. One of the features we introduced last year was to copy the information they provided in one frame to the very next frame.
This way, if an object has moved but is still present, the labeller can simply move or edit the box instead of drawing it from scratch and re-entering the class and track id information. Another change we're currently investigating is to have our machine learning system supply a set of initial boxes for the labellers to work with. The less our labellers have to manually draw, the faster they'll be able to label alarms.
We've been collecting data for a while and have learned some useful lessons along the way. When we first started, we used to show each alarm to only a single labeller. But we found that with just one labeller, if they made a mistake there was no way to catch this during the labelling process. So we decided to try a different approach. Now, an alarm is showed to two separate labellers who are asked to label the alarm independently. Then an algorithm measures how well the labels provided from both these individuals match up and tries to average them out.
If there are cases where it's still ambiguous, both sets of labels are passed on to a reviewer. These are labellers with more experience and we ask them to help consolidate the conflicting labels. These reviewers can choose to pick one label over the other or maybe merge it in a way that couldn't be done by our merging algorithm. With this approach, we've found that the quality of our data has significantly improved and there are far fewer ambiguous labels.

Above: two independent human data labelling examples, with a third image showing a machine learning algorithm's consolidation of the two attempts to create an average.
How to improve data quality
Even with this procedure in place, it's extremely important to continuously monitor the quality of our data. By having our machine learning engineers check the data periodically, we've been able to uncover issues ranging from ones as simple as bounding boxes not being tight enough, to more complex issues like a bug in the training and annotation pipeline that meant the labellers saw one set of images while the machine was provided with another, resulting in mismatched label information.
Oftentimes, by just prioritising cleaning up existing data over obtaining new data, we've seen big jumps in performance. There have been many studies on this too. For example in this work, the authors are able to reduce their error rate by almost 10% simply by removing noise from their dataset.
A common adage in machine learning is that more data is better. However, we have found that there are caveats to this. For example, for our use case, we want labels for alarms across a diverse set of views. However, some views naturally have more alarms than others. Perhaps this might be because a certain area of the view captures a busy road (an issue that can be alleviated with masking) or maybe there are just certain times where there is more activity on the site (schedules can help with this).
Regardless, we don't want our dataset to get overloaded by alarms from these high-alarming views because then the machine learning algorithm will be skewed to doing well for these views, at the cost of doing poorly on some others. To avoid this, we put a cap on how many alarms we label per view. We have an algorithm that constantly checks how many labels we have per view and once the cap has been reached, the labellers' efforts are redirected to other views.
So hopefully you now have a better understanding of the data collection and annotation procedures at Calipsa. As data is the life force of good machine learning systems, we have put a lot of work into ensuring that we gather high quality data and our data processes are going to be something we always focus on improving. This in turn will contribute to improved performances across our Pro Analytics product suite.
Want to find out more about machine learning? Why not download our FREE ebook, Machine Learning Explained, where you can discover the fundamentals of AI, neural networks, machine learning, and more.

No comments